Product managers discover opportunities, find solutions and align cross-functional teams towards the product vision. They constantly communicate the product’s potential and progress with stakeholders. As building of AI products and features becomes commonplace, product managers need the knowledge to navigate complexities involved. This paper explores the AI knowledge needed for product managers to succeed in this evolving landscape.
Introduction to AI for Product Managers
Among other things, Artificial Intelligence (AI) personalizes user experience by recommending products (e.g., ecommerce), fraud detection (credit card payments), search (google or bing), content or solutions (e.g., chatbots for sellers, buyers or customer support executives) and improves productivity, code quality and well-being of product developers (e.g., GitHub copilot). Generative AI is an AI system that can produce high quality content, specifically text, images, and audio. The first truly successful Large Language Model was GPT-3, which laid the groundwork on training models with billions of parameters. One widely used family of open-source LLMs is the Llama-3 family, available with 8 Billion and 70 Billion parameters. Understanding concepts such as neural networks helps product managers evaluate capabilities and limitations of AI powered solutions.
State of AI Applications
Following AI applications are helpful and in use today: i) Speech recognition: Siri and Alexa, ii) Handwriting recognition: Postal services for sorting mail, iii) Machine Vision: Autonomous vehicles for navigation, iv) AI in healthcare: genomic data, electronic health records, and wearables, v) Stock market prediction, vi) Guaranteeing authenticity of products through computer vision and AI, vii) summarizing customer communications through various channels for customer support agents, etc.
Following AI applications are helpful but NOT in use today: i) AI in neuroscience, ii) AI in drug discovery, iii) AI in radiology, iv) Conscious AI etc.
Following AI applications are, potentially, harmful but are in use today: i) Deep Fakes, ii) Surveillance, iii) Autonomous weapons, iv) AI in social media, v) Job displacement, etc.
Following AI applications are harmful and NOT in use today: i) Superintelligence AI, ii) AI in healthcare, iii) AI in finance, iv) AI in warfare, v) AI consciousness etc.
Foundations of AI, Machine Learning and Deep Learning1

All useful computer systems have an input, and an output, with some kind of calculation in between. Neural networks are no different. When we don’t know how something works we can try to estimate it with a model which includes parameters which we can adjust. If we didn’t know how to convert kilometers to miles, we might use a linear function as a model, with an adjustable gradient. A good way of refining these models is to adjust the parameters based on how wrong the model is compared to known true examples.
An important idea in machine learning is to moderate the updates. This moderation, has another very powerful and useful side effect. Moderation can dampen the impact of errors noise. It smooths them out.
△A = L (E/x) . The moderating factor is often called a learning rate.
Boolean logic (true =1, false =0) functions are important in computer science. Is there more malaria when it rains AND it is hotter than 35 degrees? Is there malaria when either (Boolean OR) of these conditions is true? There is another Boolean function called XOR, short for eXclusive OR, which only has a true output if either one of the inputs A or B is true, but not both. That is, when the inputs are both false, or both true, the output is false.
| Input A | Input B | Logical XOR |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Traditional computers processed data very sequentially, and in pretty exact concrete terms. There is no fuzziness or ambiguity about their cold hard calculations. Animal brains on the other hand, seemed to process signals in parallel, and fuzziness was a feature of their computation.
Neurons, transmit an electrical signal from one end to the other, from the dendrites along the axons to the terminals. These signals are then passed from one neuron to another. This is how your body senses light, sound, touch, pressure, heat, and so on. Signals from specialized sensory neurons are transmitted along your nervous system to your brain, which itself is mostly made of neurons. The very capable human brain has about 100 billion neurons! A fruit fly has about 100,000 neurons and is capable of flying, feeding, evading danger, finding food, and many more fairly complex tasks. The nematode worm has just 302 neurons, which is positively miniscule compared to today’s digital computer resources! But that worm is able to do some fairly useful tasks that traditional computer programs of much larger size would struggle to do.
Neuron takes an electrical input, and pops out another electrical signal. Neurons don’t react readily, but instead suppress the input until it has grown so large that it triggers an output. It’s like water in a cup – the water doesn’t spill over until it has first filled the cup. A function that takes the input signal and generates an output signal, but takes into account some kind of threshold is called an activation function. Mathematically, there are many such activation functions that could achieve this effect.

The S-shaped function shown below is called the sigmoid function. It is smoother than the cold hard step function, and this makes it more natural and realistic.
The sigmoid function, sometimes also called the logistic function, is y = 1 / (1 + e-x)
e is a mathematical constant 2.71828. When x is zero, e-x is 1 and y is 0.5 (half).
First thing to realize is that real biological neurons take many inputs, not just one. We saw this with Boolean logic. We combine these inputs by adding them up, and the resultant sum is the input to the sigmoid function which controls the output. This reflects how real neurons work. If the combined signal is not large enough then the effect of the sigmoid threshold function is to suppress the output signal. If the sum of x is large enough the effect of the sigmoid is to fire the neuron.
The electrical signals are collected by the dendrites and these combine to form a stronger electrical signal. If the signal is strong enough to pass the threshold, the neuron fires a signal down the axon towards the terminals to pass onto the next neuron’s dendrites. The thing to notice is that each neuron takes input from many before it, and also provides signals to many more, if it happens to be firing. One way to replicate this from nature to an artificial model is to have layers of neurons (nodes), with each connected to every other one in the preceding and subsequent layer.

What part of this architecture does the learning (L) represent? Weight is shown associated with each connection. A low weight will de-emphasize a signal, and a high weight will amplify it. So W1,2 is the weight that diminishes or amplifies the signal between node 1 and node 2 in the next layer. The network learns to improve it’s outputs by refining the link weights inside the network, some weights become zero or close to zero. Let’s imagine 2 inputs (1.0 and 0.5). Each node turns the sum of the inputs into an output using sigmoid function y = 1 / (1 + e-x ), where x is the sum of incoming signals to the neuron, and y is the output of that neuron. Let’s go with some random weights. W1,1 = 0.9, W1,2 = 0.2, W2,1 = 0.3, W2,2 = 0.8
The first layer of neural networks is the input layer and all that layer does is represent inputs (1.0 and 0.5). Let’s focus on node 1 in the layer 2. Both nodes in the fist input layer are connected to it. Those input nodes have raw values of 1.0 and 0.5. The link from the first node has a weight of 0.9. The link from the second node has a weight of 0.3. So the combined moderated input is
x = (output from the first node * link weight) + (output from the second node * link weight)
x = (1 * 0.9) + (0.5 * 0.3) = 1.05 and y = 1/(1 + e-x) = 0.7408. Similarly, we can calculate second node’s output using the sigmoid activation function. So y = 0.6457

X = W*I
W is the matrix of weights, I is the matrix of inputs.
The activation function simply applies a threshold and squishes the response to be more like that seen in biological neurons.
O = sigmoid (X)

That O written in bold is a matrix, which contains all the outputs from the final layer of the neural network. The expression X = W*I applies to the calculations between one layer and the next. If we have 3 layers, we simply do the matrix multiplication again, using the outputs of the second layer as inputs to the third layer but of course combined and moderated using more weights. The first layer is the input layer, the final layer is the output layer and the middle layer is called the hidden layer.
Xhidden = Winput_hidden * I and Ohidden = sigmoid(Xhiddden). The sigmoid activation function is applied to each element of Xhidden to produce the matrix which has the output of the middle hidden layer. No matter how many layers we have, we can treat each layer like any other – with incoming signals which we combine, link weights to moderate those incoming signals, and an activation function to produce the output from that layer.
Xoutput = Whidden_output*Ohidden
Ooutput = sigmoid(Xoutput)
The next step is to use the output from the neural network and compare it with the training example to work out an error. We need to use that error to refine the neural network itself so that it improves its outputs. Here there are 2 nodes contributing a signal to the output node. The link weights are 3.0 and 1.0. If we split the error in a way that is proportionate to these weights, we can see that 3/4 of the output error should be used to update the first larger weight, and 1/4 of the error for the second smaller weight. This method is called backpropagation.
error e1, is the difference between the desired output provided by the training data t1 and the actual output o1. The error at the second output node is e2.
e1 = ( t1 – o1),
ehidden,1 = eoutput,1 * (W11/(W11+W21)) + eoutput,2 * (W12/(W12+W22))
Backpropagation can be made more concise by using matrix multiplication (vectorize the process).

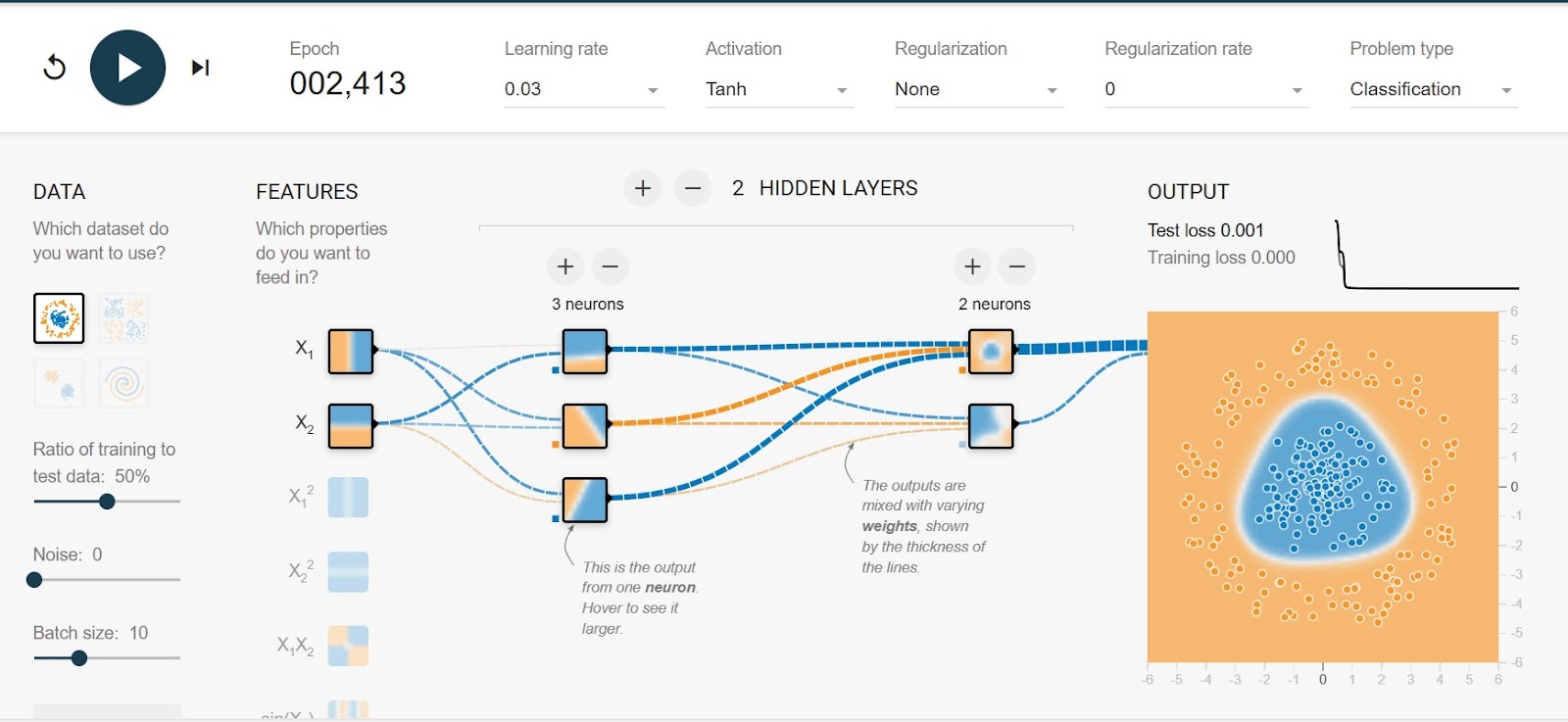
Tensorflow Playground
Sample Python Neural Network Code

Concepts of Overfitting and Underfitting in AI Models2

Generative Adversarial Networks
One network produces answers (generative). Another network distinguishes between the real and the generative answers (adversarial). Train these networks competitively, so that after some time, neither network can make further progress against the other.
Large Language Model Limitations, Prompt Engineering, Retrieval Augmented Generation (RAG) and Fine-tuning
Hallucinations: Makes statements that sound plausible, but are not true. Language models can confidently invent fake answers, especially when asked about esoteric topics or for citations and URLs. To reduce hallucinations, use prompts to limit information and have LLM answer the question with only relevant information.
LLMS also face Knowledge Cutoff date, have a limit on context length (total input + output size) and have problem comprehending structured data (e.g., data in a database table or a spreadsheet).
Prompt Engineering: Strategies and tactics for getting better results from large language models.3
- Write clear instructions.
- Instruct the model to answer using a reference text.
- Instruct the model to work out its own solution before rushing to a solution. Ask the model if it missed anything on previous passes.
- Use external tools. If a task can be done more reliably by a tool rather than by a language model, offload it to get the best of both. E.g., use booking.com to book your flight instead of trying to use an LLM to do the trick.
- Evaluate model outputs with reference to gold-standard answers.
Retrieval Augmented Generation (RAG):
By providing relevant context in the prompt, you can ask an LLM to read a piece of text/documents/website content/SQL-database/csv files .., then process it to get an answer. E.g., Chatbots equipped with RAG can answer customer inquiries more effectively. By understanding the context of a question about a product, the chatbot can retrieve relevant information from the database and provide tailored answers.
- User Input: You ask the LLM a question.
- Information Retrieval: The LLM digs through its external database to find relevant information related to your question.
- Augmented Prompt: The LLM takes your original question and combines it with the retrieved information to create a richer prompt.
- Generation: Finally, the LLM uses this enhanced prompt and its own knowledge to craft a response.
Fine-tuning6:
- Adapts a pre-trained LLM to a specific task or domain.
- Advantages: Improves performance, reduces hallucinations, and offers privacy benefits.
- Disadvantages: Requires more high-quality data and technical knowledge.
- Benefits:
- Increased accuracy and control over the LLM’s outputs.
- Reduced costs per request due to potentially smaller models.
- Improved reliability and control over uptime and latency.
- Enhanced moderation capabilities.
- Process:
- Pre-training: Train a base model on a massive dataset (e.g., The Pile) to learn language fundamentals.
- Fine-tuning: Train the base model further on a smaller, task-specific dataset to improve performance.
- Key Points:
- Fine-tuning can be done with labeled or unlabeled data.
- Generative fine-tuning is less defined but focuses on behavior changes.
- Requires identifying a task, gathering data, and training/evaluating the model iteratively.
- Data Considerations:
- More data is generally better, but quality of data and diversity are crucial.
- Real data is preferred over generated data.
- Training Process:
- Involves feeding data, calculating errors, adjusting model weights, and fine-tuning hyperparameters.
- Evaluation:
- Human evaluation, test suites, and metrics (ARC, HellaSwag, MMLU) are used to assess performance.
- Error Analysis:
- Understanding the base model’s behavior helps identify and fix errors in the data or model.
Evaluating LLMs
Assessing how well LLMs understand and respond to information is measured using, among other things, three key metrics:
1. Answer Relevance, 2. Context Relevance. and 3. Groundedness.

Source: DeepLearning.ai course material.
These metrics are crucial for understanding how well LLMs grasp and respond to information. By evaluating these aspects, developers can improve the overall quality and reliability of LLM outputs.
Responsible AI
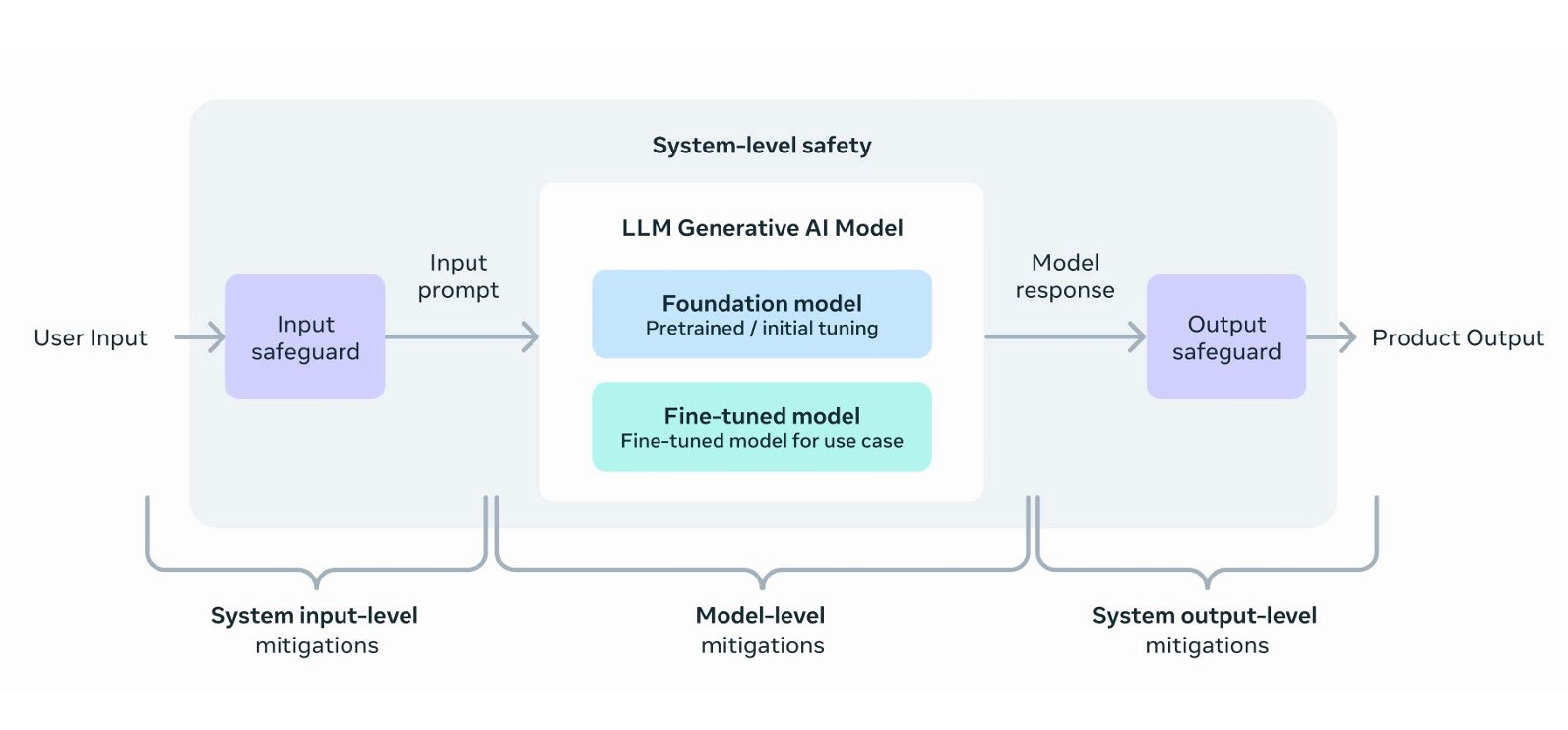
- Determine use case: Internal risk assessments help identify potential problems for specific uses of an AI product. This can involve user surveys or market analysis to understand how the product might be misused. The assessment should also define acceptable content and safety limitations to prevent the product from generating illegal, violent, or harmful outputs. For example, a policy against aiding scams might require the product to refuse to answer prompts on how to run a Ponzi scheme. Finding a balance between helpfulness and avoiding harmful content creation is an ongoing challenge.
- Model-level alignment: Steps to responsibly fine-tune an LLM for alignment:
- Prepare and upload training data: Carefully design the fine-tuning process by curating a high-quality dataset that is representative of your use case, conduct rigorous evaluations, and test your fine tuned model’s potential use via red teaming.
- Train a new-fine-tuned model: Fine tuning an LLM for safety involves various techniques including, a. Supervised Fine-tuning (SFT), Reinforcement Learning from Human Feedback (RLHF) or AI Feedback (RLAIF). Context distillation for safety helps the model associate adversarial prompts with safe responses by prefixing a safe pre prompt such as “You are a safe and responsible assistant” to the adversarial prompt, followed by fine-tuning on new outputs.
- Evaluate and improve performance: The final stage is to evaluate the fine-tuned model on a test set to measure its performance on the specific task and against safety benchmarks. Evaluation strategies and processes to improve performance can include: a. Automatic evaluation. b. Manual evaluation and c. Red teaming.
- System-level alignment: Large language models (LLMs) need safeguards to prevent misuse and ensure adherence to safety policies.
- Input Level:
- Prompt Filters: Block or modify specific prompts that might lead to unintended outputs.
- Prompt Engineering: Guide the model’s behavior by providing context and desired outputs in the prompts themselves.
- Output Level:
- Blocklists: Prevent generation of specific phrases deemed risky.
- Classifiers: Use AI to analyze and filter outputs based on their meaning to catch broader categories of unsafe content.
- Input Level:
- Build transparency and reporting mechanisms in user interactions: User interactions can provide critical feedback, which can be used for reinforcement learning. Feedback mechanisms can be as simple as positive or negative (thumbs up or thumbs down), and tailoring feedback to the types of issues that may be foreseeable based on a company’s use case.
- User Feedback Integration: User interactions, positive or negative, provide valuable data for improvement through reinforcement learning. This feedback should be tailored to the system’s potential issues.
- Transparency with Users: Be upfront with users about the AI’s limitations and potential risks. Avoid making users believe they are interacting with a human.
- User Control: Empower users by allowing them to choose from multiple outputs or even edit the generated text. This increases their sense of control over the AI’s results.
- Training Data Balance: Overly filtering training data for safety can hinder the model’s ability to handle real-world situations. A balance is needed.
- Goal Alignment: Maintain your core objective throughout development, from data collection to user feedback loops.
- Standardized Learning: Develop a systematic process to analyze user feedback and errors. This analysis should help prioritize issues and guide improvements in future iterations of the model.
By embracing the principles of transparency, accountability and user empowerment, as well as having commitment to ongoing learning and improvement, you can ensure that your AI feature is not only innovative and useful but also responsible and respectful.
Identifying Automation Opportunities
AI doesn’t automate jobs. It automates tasks. Most jobs involve a collection of many tasks. Example: Customer Service Representative tasks (and Generative AI potential) could be:
- Answer inbound phone calls from customers (Low)
- Answer customer chat queries (High)
- Check status of customer orders (Medium)
- Keep records of customer interactions (High)
- Assess accuracy of customer complaints (Low)
Conclusion
This paper provides a comprehensive overview of the knowledge required by product managers to effectively build and enhance AI products and features to solve customer and stakeholder opportunities. It explains the state of AI applications in layman’s terms and provides a foundation for AI, deep learning, and machine learning.
References
- Make Your Own Neural Network, Book by Tariq Rashid
- Stanford Class “Crash Course in AI” Tech 152: Class 2 slides
- Prompt engineering – OpenAI API
- ai.meta.com/static-resource/responsible-use-guide/
- Used summarization capabilities of Gemini LLM to reduce the size of the paper from 15 to current size.
- Fine-tuning Large Language Models, training material by DeepLearning.ai